
Kad kažemo “Filozofski fakultet”, rijetko kad vidimo monetizacijski potencijal rezultata rada njihovih timova. Zato mi je bilo iznimno zanimljivo upoznati dr. sc. Benedikta Peraka, lingvista koji se bavi digitalnom humanistikom i predaje na Odsjeku za kulturalne studije.
Naime, Laboratorij za istraživanje kulturne složenosti pri Filozofskom fakultetu u Rijeci, u suradnji sa sveučilišnim Centrom za umjetnu inteligenciju i cyber-sigurnost razvija zanimljiv i tržištu potencijalno jako atraktivan projekt EmoCNet: Računalni resursi, metode identifikacije i ontološko modeliranje komunikacije psiholoških stanja (http://emocnet.uniri.hr/).

Na ovom interdisciplinarnom projektu rade i dvije matematičarke: dr. sc. Sanda Bujačić Babić i dr. sc. Tajana Ban Kirigin s Odjela za matematiku te muzikologinja dr. sc. Diana Grgurić s Odsjeka za kulturalne studije.
Uvjerena sam da će uskoro naći svoje partnere u poduzetništvu i izgraditi lijep biznis oko ove digitalno-lingvističke priče.
Krenimo polako… 😉
Čime se bavi EmoCNet?
EmoCNet bavi se graf-analizom i reprezentacijom sintaktičko-semantičkih jezičnih uzoraka izražavanja emocija u javnom, političkom i pop-kulturnom diskurzu.
Istraživači su, znači, na temelju lingvističke teorije konstrukcijske gramatike, metoda računalne obrade jezika (NLP) i aplikacije graf-teorije razvili algoritam pod nazivom ConGraCNet, koji se može koristiti za semantičku i sentiment analizu jezičnih pojmova u nekom skupu tekstova. Algoritam se primjenjuje na hrvatski, kao i na druge europske jezike.
Znam, nije vam baš jasno, zar ne? U početku, iskreno, nije bilo ni meni. Zato i pišem ovaj blog. Pokušat ćemo sloj po sloj svladati znanstvenu složenost kako bismo preveli rezultate rada u svima razumljive ishode i mogućnosti monetizacije ove suvremene i važne tehnologije.
Netočna, ali potencijalno korisna usporedba s Google mapama
Ako bismo usporedili proces mapiranja gradova na karti s mapiranjem jezičnih pojmova putem ConGraCNeta, mogli bismo reći kako je ConGraCNet nešto poput Dijkstra algoritma, mehanizma u jezgri Google mapsa, koji u razgranatoj mreži mnogih mogućih puteva, od ishodišta do odredišta, omogućava pronalaženje najkraćeg puta. Ili poput PageRank algoritma koji je Googleu omogućio rangiranje centralnih stranica u mreži web poveznica.
Još jednom se ograđujem od doslovnosti – usporedba s Google mapama je metafora i kao takvu treba je se uzeti s ogromnom dozom rezerve.
ConGraCNet aplikacija koristi snagu graf algoritama da mapira pozicije jezičnih pojmova, pronalazi asocijativne leksičke mreže i klastere, raščlanjuje njihove višeznačnosti, definira analogne konstrukcije, računa i dodjeljuje vrijednosti sentimenta, odnosno osjećaja koji riječi pobuđuju, a sve na temelju sintaktičkih odnosa riječi, rečenica, fraza koje su obuhvaćene u korpusu obrađenih tekstova.
ConGraCNet se uhvatio u koštac s nizom jezičnih problema čije rješavanje je preduvjet za primjenu alata strojnog učenja i umjetne inteligencije u izdavaštvu, marketingu, službi za korisnike, analizi, nadzoru i unapređenju rada javne uprave i naravno, razvoju znanstvenih projekata.
Njegovi algoritmi upakirani su u dopadljivu interaktivnu aplikaciju, a rezultati stavljeni na raspolaganje developerima kroz API kako bi služili kao baza za izradu raznih aplikacija ili omogućili razne funkcije unutar postojećih rješenja.
Krenimo od kraja – primjeri upotrebe ConGraCNeta
Budući da je riječ o složenom znanstvenom algoritmu izraslom na postojećim tehnologijama obrade jezika, čitljiviji ćemo biti i korisniji ako krenemo naopačke, dajući par primjera moguće upotrebe, a tek pri kraju pokušamo objasniti i neke tehnološke aspekte.
1. ConGraCNet može biti srce razvoja AI chatbota, primjerice.
Kako razumjeti korisnička pitanja, imajući u vidu kaotičnost, višeznačnost i multidimenzionalnost jezika i ljudskog izražavanja, veliki je problem svakog chatbota, računalnog razgovornog asistenta.
ConGraCNet aplikacija nudi pomoć pri odgonetanju semantičkih i afektivnih nijansa korisničkih upita te bi AI chatbot, pogonjen podacima o tim dimenzijama, bio u stanju detektirati je li korisnik ljut, zadovoljan ili čak sarkastičan, prilagođavajući komunikaciju s njim ne samo u značenjskom, nego i emotivnom smislu.
Istraživači EmoCNet projekta pokrenuli su razvoj chatbota za Filozofski fakultet u Rijeci koji će moći poslužiti kao primjer mogućnosti ConGraCNet algoritma, a surađuju i na projektu muzejskog asistenta, chatbota čakavskog dijalekta CHAI u suradnji sa Zavičajnim muzejom Drenova.
2. Analiza emotivnog tona emailova – i predviđanje emocije buduće komunikacije u službi za korisnike
Neke od primjena jezične analize subjektivnog osjećaja teksta – sentimenta – imaju i nešto uobičajeniju uporabu u analizi afektivnog tona različitih poruka, bilo da se radi o skeniranju pristigle elektronske pošte ili povratnih informacija s foruma i društvenih mreža, što može olakšati posao korisničkoj službi i pomoći optimalno alocirati resurse.
Na primjer, identificirati gdje su korisnici ljuti – ili gdje i zašto su (ne)zadovoljni. Koje emocije pojedini problemi ili benefiti pobuđuju? Tko su najljući nezadovoljni pojedinci ili grupe – a tko su najentuzijastičniji korisnici vaših proizvoda? Što ljuti jedne, a što druge. Sve su to primjeri analiza u koje zadire razvoj ConGraCNet aplikacije.
3. Analiza raznih korpusa tekstova. Na primjer što se priča u Saboru i koje su teme zastupljene – i kod koga
Metode graf analize primjenjive su i na korpuse javnih diskurza, primjerice saborskih rasprava, govora pojedinih zastupnika ili zastupničkih klubova, čime se pojmovni modeli mogu rastaviti na osnovne jedinice, može im se dodijeliti brojčane metrike i dodati sadržajna analiza, skoro kao u medicinskim nalazima krvi.
Kojim se temama tko bavi? Koliko vremena i intenziteta posvećujemo kojim skupinama pojmova i tema? Postoje li pomaci u vrijednosnom pogledu na teme kroz vrijeme – jesmo li skloniji ili manje skloni prihvatiti novosti i uvesti nove koncepte ili i dalje vrtimo neke stare klastere pojmova poput ustaša-partizana-doma-majke-domovine?
Benedikt Perak pokazao je mogućnosti jezičnih algoritma na primjeru analize komemoracijskih govora. Iz njih je moguće iščitati kako pojedini govornici vide neke od pojmovno-ideoloških tema, njihove međusobne odnose, kao i koje su institucije uvele pojedine pojmove u javni diskurz.
Alati korpusne analize omogućuju pregled tko je uveo koju temu ili pojam, u kojem ključnom trenutku je došlo do promjene tona, značenja riječi, učestalosti njezine upotrebe i još mnogo drugih uvida koji mogu biti neiscrpno vrelo za demokratizaciju društva i istraživanja kojima je cilj optimizirati rad javne uprave.
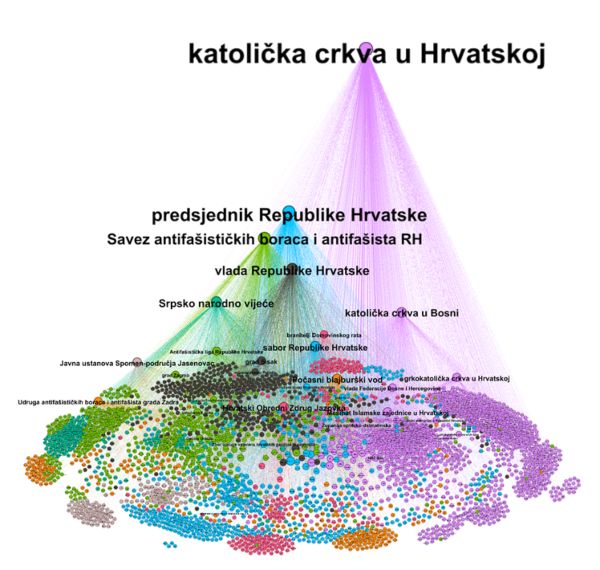
Algoritam ConGraCNet mogao bi biti u službi vrednovanja rada, npr. Turističke zajednice.
Zamislite analizu toga kako stoje Split, Zadar ili Dubrovnik u korpusu turističkih medija. S kojim destinacijama nas uspoređuju, koje pridjeve ljudi vezuju uz pojedinu destinaciju? Kakvu emotivnu dimenziju ima pojedina destinacija ili njezin dio?
Od relativno trivijalnih uvida – recimo usporedbe učestalosti spominjanja pojedine destinacije, uz usporedbu s konkurentima, preko uvida u klasteriranje (vide li Split kao destinaciju koju biraju između Madrida, Barcelona i Atene ili smo i dalje lokalni, pa nas vide tek kao mikrodestinaciju nakon što su već odlučili ići na Balkan?), alat omogućava i vrlo složene funkcije poput uvida u sentiment analizu pojmova ili praćenje promjena kroz vrijeme i niza drugih parametara.
Rječnici i edukacijska sredstva 4.0
Ovaj alat omogućava jezičnim i edukacijskim stručnjacima izradu pametnih rječnika i dosad nezamislivo bogatih edukacijskih sredstava za poučavanje ili samostalno učenje.
Zamislite rječnik koji dinamički, na temelju novostvorenih izjava, bilježi promjene značenja, tona, emotivne vrijednosti i druge parametre riječi, gotovo pa na dnevnoj razini – jer jezik je živo tkivo koje se stalno mijenja. Jedan od radova ove istraživačke skupine, primjerice, objavljen u suradnji s voditeljem Centra za istraživanja emocija u kroz-kulturnom okruženju dr. sc. Mirkom Sardelićem, bavi se semantičkim pomakom riječi ljubomora u hrvatskome, koji obuhvaća sve više i značenje pojma zavisti.
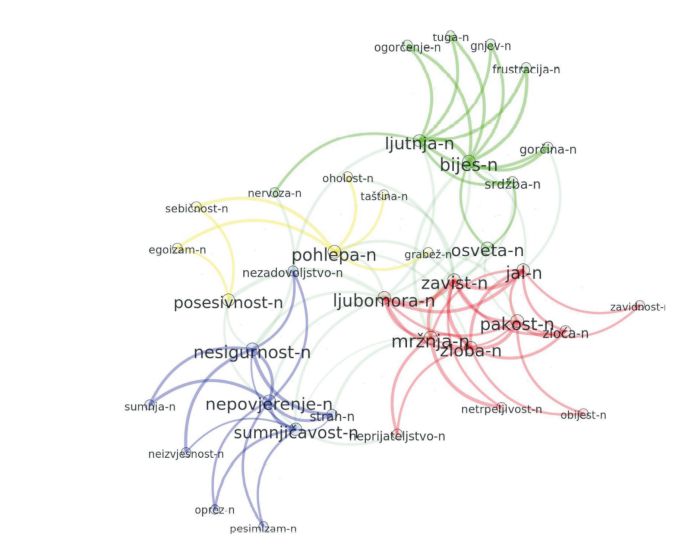
Ili zamislite mogućnost izrade rječnika neke specifične skupine govornika ili lokalnog dijalekta jednostavnom operacijom odabira korpusa u sučelju aplikacije! Osim krajnjim korisnicima, ovaj alat dobro će doći i autorima rječnika, leksikona i sličnih publikacija.
S druge strane, umjesto listanja rječnika, EmoCNet aplikacije omogućit će djeci da učeći jezik, urone u njegovu strukturu, reprezentiranu vizualnim vezama u 3D prostoru i tako pojme razne dimenzije riječi i njezinih veza.
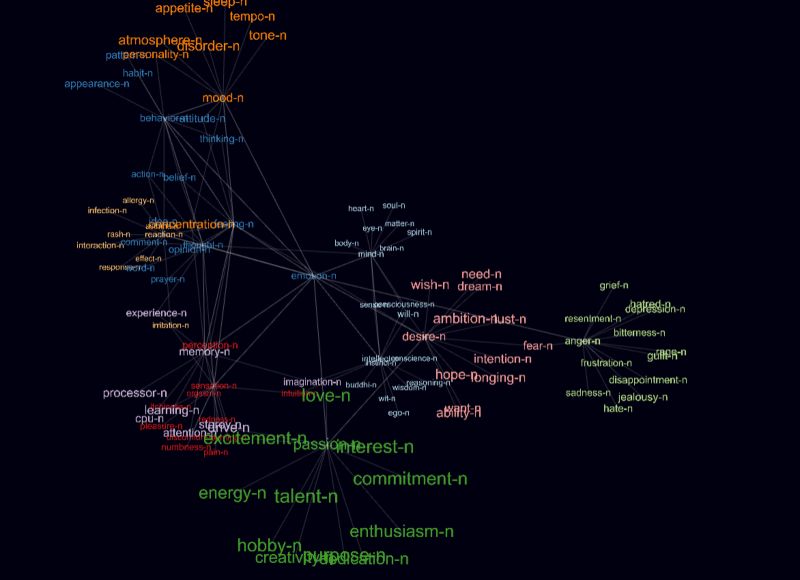
Otkud analogija s Google mapama?
Da se vratimo analogiji s Google mapama – jednom kad smo mapirali svijet, možemo lako putovati kroz njega. Tako i s jezikom – jednom kad smo mapirali jezik, možemo ga gledati, analizirati i grupirati na stotine kreativnih načina.
Povezujući pojmove, teme i specifičnosti jezika pojedinog autora, epohe, regije, ConGraCNet postaje i vrhunski izvor informacija za povjesničare i genealoge, koji analizom teksta mogu zapaziti dosad neuočene veze, relacije i sljedove uzroka i posljedica.
Detekcija slabih signala i trendova
Mogućnosti primjene su svakako i znatno šire. Primjerice, mnoge korporacije ulažu puno resursa u pokušaj detekcije ranih signala promjena na tržištu koje se manifestiraju ulaskom novih pojmova u jezik, ili u klastere gdje dosad nisu bile vidljive, kao i promjenama u emotivnom tonu riječi.
Da budemo banalni – možda je zgodno na vrijeme primijetiti kako ljudi uz “hamburger” sve više unose pojam “avokado” ili “veganski”, ili kako pojam “tajice” mijenja emotivno značenje, sugerirajući da predmet “ulazi” ili “izlazi” iz mode.
Promjene u učestalosti korištenja riječi, njihovim parametrima emotivnih vrijednosti ili pripadanja raznim klasterima zapravo su provjerljivi i znanstveno utemeljeni signali promjena trendova, što su jako bitne informacije kompanijama koje uvijek žele na tržištu biti najbolje i prve.
Ovo nije iscrpan popis mogućih primjena ovog alata; no vjerujem da ste stekli dojam o čemu se radi.
A kako ConGracNet radi?
Za tehnološki znatiželjno čitateljstvo bit će zanimljivo kako su Benedikt Perak i njegov tim izgradili vlastiti algoritam koji na temelju snage sintaktičkih veza između riječi u pisanim tekstovima koje obrađuje, dodjeljuje značenjske vrijednosti izražene u nizu numeričkih parametara, a zatim, koristeći postojeće semantičke i sentiment rječnike propagira vrijednosti koje nam pomažu da razumijemo primjerice pozitivnost ili negativnost riječi, pobuđeno ili mirno stanje, koliko riječ privlači ili ne privlači pažnju, kao i neke druge dimenzije afektivnih fenomena.
Tako označene riječi daju algoritmu građu za atribuiranje parametara novih ili dosad nemapiranih riječi prema logici njihovih međusobnih veza i odnosa, iščitanih iz korpusa tekstova.
No, jezik je složen – riječi imaju više konotacija i značenja, a i koriste se u različitim kontekstima. ConGraCNet pronašao je način kako to detektirati i vizualno prikazati. Za primjer donosimo analizu klastera i emotivne vrijednosti pojma “pride” (hr. ponosa) u engleskom jeziku. Kao i u hrvatskom, i u engleskom ta riječ može imati pozitivno i negativno značenje, odnosno pobuđivati potpuno različit set emotivnih stanja. Funkcija razumijevanja i mapiranja takvih jezičnih fenomena važna je jer omogućava algoritmu da razumije dublje nijanse jezika i time pripremi AI za bolje razumijevanje i suvisliji razgovor s ljudima.
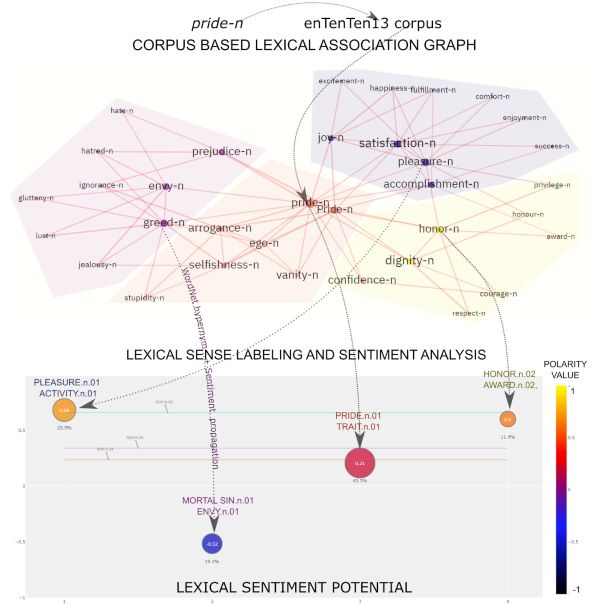
u engleskom web korpusu.
Rezultati evaluacije
Rezultati evaluacije, objavljeni nedavno u cijenjenom časopisu Mathematics, pokazuju da ConGraCNet sustav generira sentiment vrijednosti koje govornicima su za određene riječi čak prihvatljivije nego one izvornih sentiment rječnika. To pokazuje da je algoritam riječkog tima vrlo uspješno svladao neke od izazova mapiranja jezika i otišao korak naprijed u odnosu na postojeća rješenja.
Lijepo je vidjeti kako riječka humanistika radi velik iskorak prema integraciji humanistike u cjelokupnu digitalnu transformaciju društva, kao i to da se projekt razvija u okrilju projekta riječkog sveučilišta The Center for Artificial Intelligence and Cybersecurity, čiji je cilj olakšati transfer znanja iz znanstvenih voda u poduzetništvo. Nadamo se da se će puno dobrih vijesti iz hrvatske digitalne humanistike uskoro pridružiti valovima pozitivnih novosti iz svijeta domaćeg tehnološkog poduzetništva.






